비유
삶은 도전으로 가득합니다.
지난주, 이사를 하려던 참에 갑자기 비가 내리기 시작했습니다. 비를 맞으면 안 된다고 생각했고, 그래서 우산을 챙겼습니다.
간단하죠? 하지만 이 작은 결정에는 강력한 무언가가 담겨 있습니다.
인간은 끊임없이 주변 세계를 관찰하고, 상황에 대해 추론하며, 그에 맞게 행동합니다.
이 직관적인 관찰 → 추론 → 행동의 순환이 바로 ReAct 에이전트가 모방하도록 설계된 것입니다.
이 글에서는 LangGraph를 사용하여 엔드투엔드 ReAct 에이전트를 구축하고, 실용적이고 의미 있는 문제에 적용하는 과정을 단계별로 살펴보겠습니다.
ReAct 프레임워크 소개 (생성형 AI 맥락에서)
ReAct는 Reasoning(추론)과 Acting(행동)의 줄임말입니다. ReAct 에이전트는 핵심적으로 인간이 문제에 접근하는 방식을 모방합니다:
- 관찰(Observation) — 에이전트가 환경을 인식하거나 입력을 받습니다.
- 추론(Reasoning) — 가능한 행동을 내부적으로 생각하고, 선택지를 평가하며, 결과를 예측합니다.
- 행동(Action) — 마지막으로 데이터베이스 조회, API 호출, 응답 생성 등 실제 행동을 취합니다.
이 순환을 통해 에이전트는 고정된 지시 집합을 따르는 것이 아니라, 논리와 행동을 결합하여 복잡한 과제를 해결하며 동적으로 적응할 수 있습니다.
예를 들어, 여행 계획을 돕는 ReAct 에이전트를 상상해 보세요:
- 관찰: 사용자가 다음 달 파리로 여행을 원합니다.
- 추론: 항공편, 숙박, 비자 요건을 확인합니다.
- 행동: 최선의 옵션을 제안하고 요청 시 항공권을 예약합니다.
행동하기 전에 추론함으로써, ReAct 에이전트는 더 유연하고 강인하며 실제 시나리오를 효과적으로 처리할 수 있습니다.

자 이제 실제 일어날 수 있는 Case를 가지고 ReAct 기반 Agent를 만들어 보자. 전체 노트는 여기 참조.
문제 정의
문제:
근처 병원을 찾거나 신뢰할 수 있는 의료 정보를 얻는 것은 특히 위치나 진료 과목 등 구체적인 정보가 없을 때 시간이 많이 걸릴 수 있습니다. 기존 시스템은 정적인 데이터를 제공하거나 여러 번의 수동 검색을 요구하는 경우가 많습니다.
제안 솔루션:
사용자에게 누락된 정보를 묻고, 근처 병원을 찾고, 스마트 도구와 단계적 추론을 사용하여 빠르고 정확한 의료 정보를 제공하는 대화형 의료 어시스턴트를 제안합니다.
기술 스택:
- Python
- LangGraph
- LangChain
- Chroma DB
- SerperAPI (웹 검색)
- OpenAI API (LLM)
- Geocoding API (사용자 위치의 지리 좌표 획득)
필요한 모듈 불러오기
import pandas as pd
import numpy as np
import json
import re
from typing import List, Dict, Any, Tuple
import faiss
from sentence_transformers import SentenceTransformer
from openai import OpenAI
import time
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
import seaborn as sns
from dotenv import load_dotenv
import openai
import os
import chromadb
import sqlite3
from langchain_community.utilities import GoogleSerperAPIWrapper
from math import radians, cos, sin, sqrt, atan2
# ✅ 환경 변수 불러오기
load_dotenv()
openai_api_key = os.getenv("OPEN_AI_KEY")
SERPER_API_KEY = os.getenv("SERPER_API_KEY")
GEOCODE_API_KEY = os.getenv("GEOCODE_API_KEY")데이터 불러오기
A. 질문 & 답변 데이터
다양한 건강 주제에 대한 약 15,000개의 질문-답변 쌍이 포함된 의료 Q&A 데이터를 사용합니다. 출처: Kaggle. 실험을 위해 500개 행을 샘플링합니다.
## 데이터 1: 종합 의료 Q&A 데이터셋 읽기
df_qa = pd.read_csv("medical_q_n_a.csv")
## 데이터가 16,407개 행이므로 실험을 위해 500개 행을 샘플링합니다
df_qa = df_qa.sample(500, random_state=0).reset_index(drop=True)
# 텍스트를 결합하여 벡터 DB용 데이터프레임 준비
df_qa['combined_text'] = (
"Question: " + df_qa['Question'].astype(str) + ". " +
"Answer: " + df_qa['Answer'].astype(str) + ". " +
"Type: " + df_qa['qtype'].astype(str) + ". "
)
df_qa.head()
B. 미국 병원 데이터
미국 병원에 관한 정보(위치, 유형, 병상 수 등)를 포함하는 데이터셋입니다. 출처: Kaggle.
## 데이터 2: 미국 병원 데이터셋 읽기
df_hospital = pd.read_csv("Hospitals.csv")
print(df_hospital.shape)
df_hospital[["LATITUDE", "LONGITUDE", "CITY", "STATE", "TYPE", "NAME",
"ADDRESS", "BEDS", "WEBSITE", "COUNTRY"]].head()
벡터 스토어 설정
Q&A 쌍 데이터를 ChromaDB(오픈소스 벡터 스토어)에 업로드합니다. 이는 나중에 ReAct 에이전트가 사용자의 건강 관련 질문에 답할 때 지식 베이스로 사용됩니다.
ChromaDB 클라이언트 및 컬렉션 생성
컬렉션은 데이터베이스의 테이블과 같습니다.
import chromadb
# ChromaDB 설정
client = chromadb.PersistentClient(path="./chroma_db")
# 의료 Q&A 데이터셋용 컬렉션 1
collection1 = client.get_or_create_collection(name="medical_q_n_a")컬렉션에 데이터 추가
ChromaDB는 sentence-transformers의 기본 벡터 임베딩 모델을 사용합니다.
# 컬렉션에 데이터 추가
# chromadb는 기본 임베딩(sentence transformers)을 사용합니다
collection1.add(
documents=df_qa['combined_text'].tolist(),
metadatas=df_qa.to_dict(orient="records"),
ids=df_qa.index.astype(str).tolist(),
)ChromaDB 테스트
query = "What are the treatments for Kawasaki disease ?"
results = collection1.query(query_texts=[query], n_results=3)
print(results)웹 검색 API 설정
SerperAPI를 웹 검색에 사용합니다. 주어진 쿼리에 대해 구글 검색 결과를 반환합니다.
from langchain_community.utilities import GoogleSerperAPIWrapper
SERPER_API_KEY = os.getenv("SERPER_API_KEY")
search = GoogleSerperAPIWrapper()
# 구글 검색 API 테스트
search.run(query="What are the various vaccines of COVID-19")Geocode API 설정
Geocode API를 사용하여 주어진 위치의 위도와 경도를 얻습니다. 사용자 위치를 기반으로 가장 가까운 병원을 찾는 데 사용됩니다.
import requests
def get_coordinates(address):
url = "https://geocode.maps.co/search"
params = {"q": address, "api_key": "GEOCODE_API_KEY"}
response = requests.get(url, params=params)
if response.status_code == 200:
data = response.json()
if data:
lat = data[0]["lat"]
lon = data[0]["lon"]
print(f"Latitude: {lat}, Longitude: {lon}")
return lat, lon
else:
print("No results found.")
else:
print(f"Error: {response.status_code}")
# 사용 예시
get_coordinates("new york city")출력:
Latitude: 40.7127281, Longitude: -74.0060152OpenAI API 설정
gpt-4o-mini를 사용하도록 OpenAI API 클라이언트를 설정합니다. 이 소형 언어 모델(SLM)이 에이전트의 두뇌 역할을 합니다.
from openai import OpenAI
openai_api_key = os.getenv("OPEN_AI_KEY")
def get_llm_response(prompt: str) -> str:
"""LLM에서 응답을 가져오는 함수"""
from openai import OpenAI
client_llm = OpenAI(api_key=openai_api_key)
response = client_llm.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
## LLM 응답 테스트
prompt = "Explain the impact of GenAI on healthcare in 30 words"
response = get_llm_response(prompt)
print(response)도구(Tools) 정의
ReAct 에이전트를 위한 4가지 무상태(stateless) 도구를 Python 함수로 정의합니다.
A. 컨텍스트 검색
주어진 쿼리에 대해 벡터 데이터베이스(ChromaDB)에서 관련 청크를 반환합니다.
def retrieve_context_q_n_a(query: str):
"""무상태: 관련 의료 Q&A 컨텍스트를 반환합니다."""
print("---도구 호출: 컨텍스트 검색 중---")
results = collection1.query(query_texts=[query], n_results=3)
context = "\n".join(results["documents"][0])
return {"context": context, "source": "Medical Q&A Collection"}B. 웹 검색
Serper API를 사용하여 주어진 쿼리에 대한 구글 검색 결과를 반환합니다.
def web_search(query: str):
"""무상태: 웹 검색 결과를 반환합니다."""
print("---도구 호출: 웹 검색 수행 중---")
search_results = search.run(query=query)
print(search_results)
return {"context": search_results, "source": "Web Search"}C. 사용자에게 질문
에이전트가 사용자에게 위치 등의 후속 질문을 해야 할 때 이 함수를 호출합니다. 노트북 환경에서는 사용자가 정보를 입력할 수 있는 입력 위젯을 표시합니다.
def ask_user(question: str):
"""사용자에게 입력을 요청하고 응답을 반환합니다."""
print(f"---사용자 입력 필요---\n{question}")
answer = input(f"{question}: ") # 노트북을 일시 중지하고 입력을 기다립니다
return {"context": answer, "source": "User Input"}D. 가장 가까운 병원 검색
미국 내 가장 가까운 병원을 검색하기 위해 이 도구를 호출합니다.
def search_nearest_hospital(user_location: str, specialty: str = None, top_n: int = 3):
"""무상태: 위치/진료과에 기반하여 가장 가까운 병원을 반환합니다."""
print("---가장 가까운 병원 검색 중---")
user_coords = get_coordinates(user_location)
if not user_coords:
return {"error": "좌표를 가져올 수 없습니다"}
user_lat, user_lon = user_coords
def haversine(lat1, lon1, lat2, lon2):
lat1, lon1, lat2, lon2 = map(radians, [float(lat1), float(lon1), float(lat2), float(lon2)])
dlon = lon2 - lon1
dlat = lat2 - lat1
a = sin(dlat/2)**2 + cos(lat1)*cos(lat2)*sin(dlon/2)**2
c = 2 * atan2(sqrt(a), sqrt(1-a))
return 6371 * c # km
if specialty:
filtered_df = df_hospital[df_hospital['TYPE'].str.contains(specialty, case=False, na=False)]
else:
filtered_df = df_hospital.copy()
filtered_df['distance_km'] = filtered_df.apply(
lambda row: haversine(user_lat, user_lon, row['LATITUDE'], row['LONGITUDE']), axis=1
)
nearest = filtered_df.sort_values('distance_km').head(top_n)
nearest["distance_km"] = nearest["distance_km"].round(2)
results = nearest[['NAME','ADDRESS','CITY','STATE','TYPE','BEDS','WEBSITE','distance_km']].to_dict(orient='records')
return {"context": results, "source": "Hospital Search"}ReAct 에이전트 정의
이제 시스템의 두뇌인 ReAct 에이전트를 정의합니다.
먼저 TypedDict를 사용하여 AgentState를 정의하고, LLM 호출을 위한 call_model 함수를 정의합니다.
여기서 가장 중요한 부분은 프롬프트 기법입니다. 에이전트가 최종 답변을 얻을 때까지 관찰 → 생각 → 행동 루프를 따르도록 안내하는 ReAct 스타일 프롬프팅 기법을 사용합니다.
call_model 함수는 현재 대화 상태(사용자 쿼리, 이전 도구 출력, 사용 가능한 도구)를 LLM에 전송하여 다음 단계를 결정하도록 요청합니다 — 다음으로 호출할 도구(인자 포함)를 선택하거나 최종 답변(ANSWER)을 제공합니다. 그런 다음 워크플로우가 다음 단계에서 계속될 수 있도록 모델의 응답을 상태에 저장합니다.
import json
from math import radians, cos, sin, sqrt, atan2
from langgraph.graph import StateGraph, END
from typing import TypedDict
# === 상태 스키마 ===
class AgentState(TypedDict):
query: str
last_agent_response: str
tool_obervations: list
num_steps: int
user_location: str # 후속 위치 정보를 위한 선택적 필드
# === LLM 호출 ===
def call_model(state: dict) -> dict:
print("\n")
print("=== STEP", state.get("num_steps", 0), "===")
print("---LLM 모델 호출 중---")
query = state.get("query", "")
tool_obervations = "\n".join(state.get("tool_obervations", []))
user_location = state.get("user_location", "")
tools_list = """
사용 가능한 도구:
1. retrieve_context_q_n_a
설명: 관련 의료 Q&A 문서를 검색합니다.
인자: query (문자열)
2. search_nearest_hospital
설명: 가장 가까운 병원을 찾습니다.
인자: user_location (문자열), specialty (문자열, 선택), top_n (정수, 선택)
3. web_search
설명: 웹 검색을 수행합니다.
인자: query (문자열)
4. ask_user
설명: 사용자에게 누락된 정보를 요청합니다.
인자: question (문자열)
"""
prompt = f"""
당신은 다음 도구에 접근할 수 있는 의료 어시스턴트입니다:
{tools_list}
사용자 쿼리: "{query}"
이전 도구 관찰 결과:
{tool_obervations}
지침:
1. 항상 THOUGHT(생각)으로 시작한 다음, (ACTION과 ARGUMENTS) 또는 ANSWER를 결정합니다.
2. 이전 tool_obervations를 주의 깊게 확인하여 답변이 이미 있는지 확인합니다.
3. 없다면, 더 많은 정보를 수집하기 위해 가장 관련성 높은 도구를 선택합니다.
4. 필요한 정보가 없으면(예: 사용자 위치), 'ask_user'를 사용합니다.
5. 충분한 정보 없이 일반 지식이나 가정에 기반하여 답변하지 마십시오.
6. ARGUMENTS는 키가 큰따옴표로 묶인 유효한 JSON이어야 합니다.
7. 지정된 형식 외에 아무것도 추가하지 마십시오.
...
"""
response = get_llm_response(prompt)
state["last_agent_response"] = response
state["num_steps"] += 1
print(response)
return state도구 호출 함수
call_tool 함수는 모델의 마지막 응답을 읽어 어떤 도구를 사용해야 하는지(웹 검색, 병원 조회 등) 파악하고, JSON 인자를 추출한 다음 해당 입력으로 도구를 호출합니다. 그런 다음 도구의 결과나 사용자 응답을 워크플로우의 다음 단계를 위해 상태에 저장합니다.
# === 도구 호출자 ===
def call_tool(state: dict) -> dict:
action_text = state.get("last_agent_response", "")
if "ACTION:" not in action_text:
state.setdefault("tool_obervations", []).append(f"[액션 없음: {action_text}]")
return state
print(f"---도구 호출 중---")
tool_name = action_text.split("ACTION:")[1].split("\n")[0].strip()
print(f"호출할 도구: {tool_name}")
args = {}
if "ARGUMENTS:" in action_text:
args_text = action_text.split("ARGUMENTS:")[1].strip()
if args_text.startswith("{"):
brace_count = 0
end_index = 0
for i, char in enumerate(args_text):
if char == "{":
brace_count += 1
elif char == "}":
brace_count -= 1
if brace_count == 0:
end_index = i + 1
break
args_text = args_text[:end_index]
try:
args = json.loads(args_text)
print(f"파싱된 인자: {args}")
except json.JSONDecodeError:
print(f"JSON 인자 파싱 실패: {args_text}")
state.setdefault("tool_obervations", []).append(f"[인자 파싱 실패: {args_text}]")
args = {}
tool_map = {
"retrieve_context_q_n_a": retrieve_context_q_n_a,
"search_nearest_hospital": search_nearest_hospital,
"web_search": web_search,
"ask_user": ask_user
}
if tool_name in tool_map:
results = tool_map[tool_name](**args)
if tool_name == "ask_user":
state.setdefault("tool_obervations", []).append(f"[사용자 입력: {results['context']}]")
if "location" in args.get("question", "").lower():
state["user_location"] = results["context"]
else:
state.setdefault("tool_obervations", []).append(f"[{tool_name} 결과: {results['context']}]")
state["last_tool_results"] = results
print(results)
return state
state.setdefault("tool_obervations", []).append(f"[알 수 없는 도구: {tool_name}]")
return state종료 조건 설정
should_continue 함수는 모델의 최신 응답에 ANSWER가 포함되어 있는지(즉, 작업이 완료되었는지) 확인합니다. "ANSWER:"를 찾으면 워크플로우를 종료하고, 그렇지 않으면 다음 단계로 계속 진행합니다.
# === 계속 여부 판단 ===
def should_continue(state: dict) -> str:
last_agent_response = state.get("last_agent_response", "")
if "ANSWER:" in last_agent_response.upper():
print("마지막 응답에서 답변을 찾았습니다. 워크플로우를 종료합니다.")
return "end"
print("--워크플로우를 계속합니다.")
return "continue"그래프 구성
이 코드는 의료 어시스턴트의 작동 방식을 제어하는 워크플로우 그래프를 구성합니다. 에이전트(LLM 추론)와 도구(함수 호출)라는 두 가지 주요 단계를 정의하고, 에이전트가 ANSWER로 프로세스가 종료될 때까지 생각과 행동을 교대로 수행하도록 연결합니다.
# === 워크플로우 그래프 ===
workflow = StateGraph(state_schema=AgentState)
workflow.add_node("agent", call_model)
workflow.add_node("tools", call_tool)
workflow.set_entry_point("agent")
workflow.add_conditional_edges(
"agent",
should_continue,
{"continue": "tools", "end": END}
)
workflow.add_edge("tools", "agent")
agentic_graph = workflow.compile()
# === 시각화 ===
from IPython.display import Image, display
display(Image(agentic_graph.get_graph().draw_mermaid_png()))
ReAct 에이전트가 완성되었습니다! 이제 에이전트를 테스트해 보겠습니다.
ReAct 에이전트 테스트
쿼리 1: 의료 질문
agent_state = {
"query": "What are the symptoms of HIV virus?",
"last_agent_response": "",
"tool_obervations": [],
"num_steps": 0
}
result = agentic_graph.invoke(agent_state)출력 요약:
- STEP 0: 에이전트가 먼저
retrieve_context_q_n_a도구를 호출합니다. - STEP 1: 컨텍스트에서 적절한 답변을 찾지 못하자
web_search도구를 호출합니다. - STEP 2: 웹 검색 결과를 바탕으로 최종 답변을 제공합니다.
최종 답변: HIV의 일반적인 증상 — 초기/급성(감염 후 2~4주): 발열, 인후통, 림프절 부종, 발진, 피로, 근육 및 관절통, 두통. 만성기: 대부분 증상이 없거나 경미. 진행기(AIDS): 급격한 체중 감소, 반복적인 발열, 심한 야간 발한, 극심한 피로, 지속적인 림프절 부종, 만성 설사, 구강 또는 생식기 궤양.
에이전트는 총 3번의 LLM API 호출을 사용했습니다.

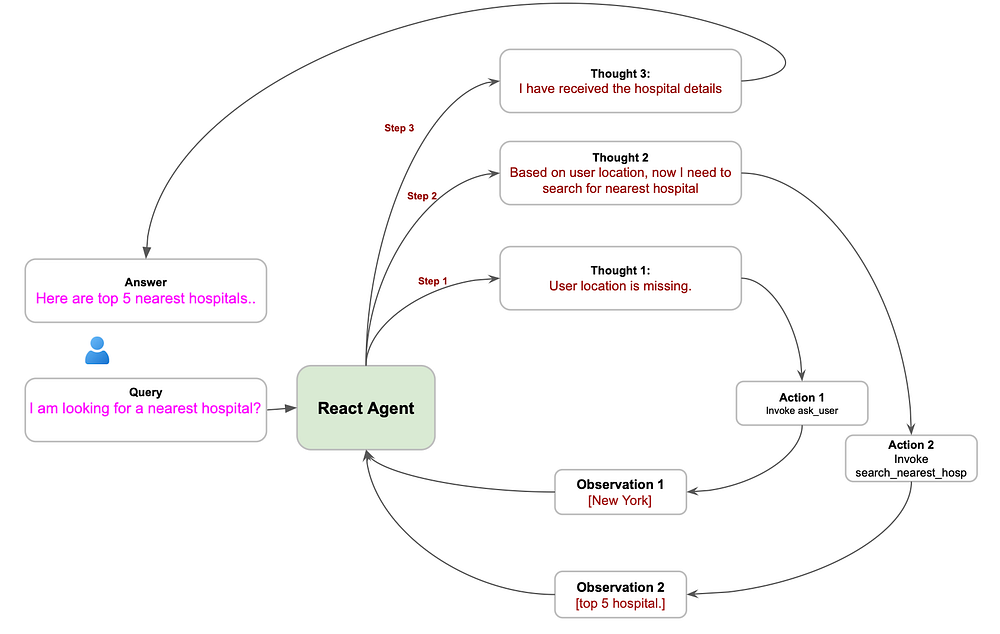
쿼리 2: 병원 관련 질문
agent_state = {
"query": "I am looking for a nearest hospital?",
"last_agent_response": "",
"tool_obervations": [],
"num_steps": 0,
"user_location": ""
}
result = agentic_graph.invoke(agent_state)출력 요약:
- STEP 0: 에이전트가 위치 정보가 없어
ask_user도구를 호출합니다. - STEP 1: 사용자가 "Newyork"을 입력하자
search_nearest_hospital도구를 호출합니다. - STEP 2: 가장 가까운 병원 5곳을 포함한 최종 답변을 제공합니다.
이 경우에도 총 3번의 LLM API 호출을 사용했습니다.
마무리
이 에이전틱 워크플로우는 추론과 도구 사용을 반복 루프에 통합하여 AI가 지능적으로 생각하고, 결정하고, 행동할 수 있게 합니다.
처음부터 끝까지의 코드는 여기 참조
LLM 의사결정(call_model), 외부 도구 실행(call_tool), 제어 메커니즘(should_continue)을 결합함으로써 동적이고 다단계 문제 해결이 가능해집니다. 워크플로우 그래프는 프로세스를 투명하고 모듈식으로 만들어, 어시스턴트가 자율적으로 누락된 정보를 수집하고, 웹 검색을 수행하거나, 최종 답변을 자신 있게 제공하기 전에 사용자에게 명확한 정보를 요청할 수 있게 합니다.
다음 단계
- 향상된 오류 처리: 에이전트가 때로 필요한 형식으로 출력을 생성하지 못하는 경우가 있습니다. 일관된 응답을 보장하기 위해 추가적인 프롬프트 튜닝과 검증이 필요합니다.
- 메모리 처리: 에이전트가 여러 세션에서 컨텍스트를 유지할 수 있도록 단기 및 장기 메모리를 구현합니다.
- 프론트엔드 통합: LangGraph 기반 에이전트는 견고한 백엔드로서 챗봇이나 다른 대화형 사용자 인터페이스에 통합할 준비가 되어 있습니다.
맺음말
ReAct 에이전트는 추론("생각")과 행동("실행")을 구조화된 루프로 효과적으로 결합하여 단계별 문제 해결을 가능하게 합니다. 사고 생성과 도구 실행을 교대로 수행함으로써 정보를 수집하고, 결과를 검증하며, 정확하고 맥락에 맞는 답변을 제공할 수 있습니다. 이 접근 방식은 해석 가능성을 높이고, 오류를 줄이며, 보다 자율적이고 목표 지향적인 AI 동작을 가능하게 합니다.
'최신 AI' 카테고리의 다른 글
| RAG (Retrieval-Augmented Generation) 완벽 가이드 (0) | 2026.03.10 |
|---|---|
| 15분만에 LangGraph로 챗봇 만들기 (0) | 2026.03.09 |
| 가장 쉽게 이해할 수 있는 LangChain 설명 (0) | 2026.02.20 |
| LangGraph로 AI 에이전트 구축하기 (0) | 2026.02.10 |
| LangGraph 사용법 (0) | 2026.02.10 |



