대부분의 RAG 실패는 잘못된 청크에서 시작된다.
이 기술 문서를 검색 품질을 망치지 않고 분할하는 방법을 소개한다.

팀들은 임베딩 모델, 벡터 데이터베이스, 프롬프트 설계를 놓고 몇 주씩 논쟁한다. 그러면서 정작 중요한 런북은 임의로 400토큰 단위로 잘라놓고, 왜 검색이 이상한지 의아해한다. 이런 시스템에서 가장 먼저 망가지는 건 모델이 아니다. 청크 경계다.
핵심 개념: 검색은 문서가 아니라 청크 단위로 동작한다
대부분의 사람들은 RAG 시스템이 문서 전체를 검색한다고 생각한다. 하지만 실제로는 전혀 다르게 동작한다.
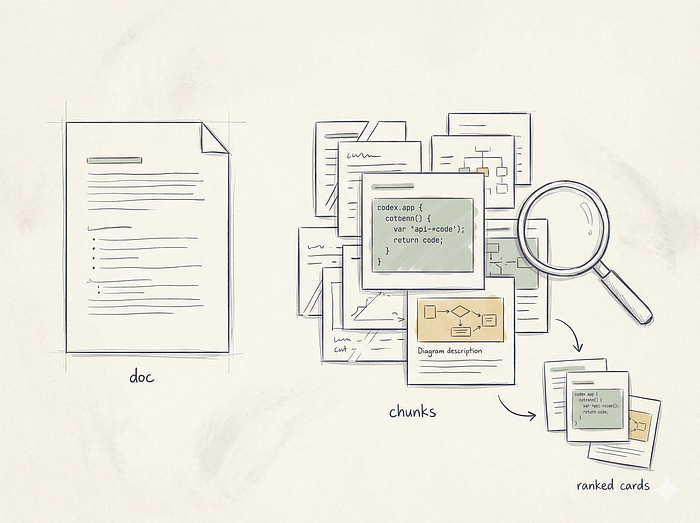
인덱스에는 청크가 들어간다. 리트리버는 청크를 스코어링한다. 리랭커는 청크를 재정렬한다. 프롬프트에는 청크가 들어간다. 모델은 청크를 기반으로 답변한다.
벡터 데이터베이스는 당신이 넣어준 텍스트 문자열만 알고 있다. 앞뒤 문단은 명시적으로 관계를 설정하지 않으면 존재하지 않는다. 원본 문서가 아무리 잘 쓰여 있어도, 청크가 조각나 있으면 검색 품질은 이미 망가진 것이다.
좋은 청크란 무엇인가?
- 하나의 일관된 개념을 담고 있다
- 절차적 단계 시퀀스를 하나로 유지한다
- 경고(Warning)를 그것이 적용되는 단계와 함께 둔다
- 코드 예제를 그것을 설명하는 텍스트와 함께 둔다
나쁜 청크란 무엇인가?
- 토큰 할당량을 채우기 위해 관련 없는 주제를 합쳐놓는다
- 절차를 중간에 잘라놓는다
- 명령어와 경고를 분리한다
- 옆 청크가 없으면 의미를 알 수 없는 단편을 만들어낸다
청킹은 크기의 문제가 아니다. 검색 단위에서 의미를 보존하는 문제다.
주요 청킹 전략들
1. 고정 크기 청킹 (Fixed-size Chunking)
가장 기본적인 방법이다. N개의 문자 혹은 토큰마다 텍스트를 자른다.
구현이 쉽고 빠르다는 장점이 있다. 거의 모든 프레임워크에 기본으로 내장되어 있다. 소설처럼 균일한 산문 말뭉치에서는 어느 정도 쓸 만하고, 프로토타입을 빠르게 만들 때 쓰기 좋다.
하지만 기술 문서에는 완전히 실패한다. 코드가 많은 문서를 망가뜨리고, 목록이나 표가 있는 문서를 엉망으로 만든다. 배포 가이드에 이 방법을 쓰면 명령어는 한 청크에, 주의사항은 다음 청크에 들어가게 된다.
def chunk_fixed(text: str, size: int = 400, overlap: int = 50) -> list[str]:
words = text.split()
chunks = []
i = 0
while i < len(words):
chunks.append(" ".join(words[i : i + size]))
i += size - overlap
return chunks
이 코드는 빠르다. 하지만 자르는 텍스트의 구조를 완전히 무시한다. 그냥 공백을 세고 배열을 자를 뿐이다.

2. 재귀적 청킹 (Recursive Chunking)
조금 더 영리한 방법이다. 단어를 세는 대신, 더 큰 의미 단위부터 분할을 시도한다. 헤딩을 찾고, 해당 섹션이 너무 크면 문단으로, 문단이 너무 크면 문장으로 재귀적으로 내려간다.
자연스러운 경계를 더 잘 보존하기 때문에 고정 크기보다는 낫다. 문단 단위로 잘리기 때문에 LLM이 읽기에도 훨씬 좋다.
다만, 헤딩 같은 구조적 표시자가 온전한 의미 단위를 반드시 포착하지는 않는다. 문서가 구조적으로 지저분할 수 있고, 마크다운의 헤딩 레벨이 일관되지 않을 수도 있다.
import re
def chunk_recursive(text: str, max_tokens: int = 512) -> list[str]:
separators = [
r"\n#{1,6}\s", # 헤딩
r"\n\n", # 문단
r"(?<=\.)\s", # 문장
]
return _split_recursive(text, separators, max_tokens)
def _split_recursive(text: str, seps: list[str], max_t: int) -> list[str]:
if len(text.split()) <= max_t or not seps:
return [text.strip()] if text.strip() else []
parts = re.split(seps[0], text)
chunks = []
for p in parts:
if len(p.split()) <= max_t:
chunks.append(p.strip())
else:
chunks.extend(_split_recursive(p, seps[1:], max_t))
return [c for c in chunks if c]
구조가 없는 말뭉치에서는 좋은 기본값이지만, 구조를 진짜로 이해하지는 못한다.
3. 시맨틱 청킹 (Semantic Chunking)
크기나 구두점이 아닌, 주제나 의미의 변화를 기반으로 분할하는 방법이다.
대표적인 구현 방식은 다음과 같다. 텍스트를 개별 문장으로 쪼갠다. 모든 문장에 대해 임베딩 벡터를 계산한다. 연속된 문장들의 코사인 유사도를 비교한다. 유사도가 특정 임계값 아래로 떨어지면 주제가 바뀐 것으로 보고 청크 경계를 만든다.
의미를 더 잘 보존하고 임의적인 단편화를 줄여준다는 장점이 있다. 주제가 자주 바뀌는 법률 계약서나 장문의 리서치 리포트처럼, 레이아웃보다 주제 경계가 중요한 말뭉치에 잘 맞는다.
다만 비용이 크다. 말뭉치 전체의 모든 문장을 임베딩해야 하므로, 백만 개의 문장이 있다면 백만 번의 API 호출이 필요하다. 경계가 블랙박스 임베딩 모델에 의해 결정되기 때문에 평가 없이는 추론하기 어렵다.
4. 구조 인식 청킹 (Structure-aware Chunking)
기술 문서에 가장 잘 맞는 방법이다. 문서 구조 자체를 명시적으로 활용한다. 헤딩, 소제목, 번호가 매겨진 절차, 코드 블록, 표, 경고 문구 등을 파싱한다.
마크다운 파일에서 > **Warning**으로 시작하는 블록은 바로 앞 문단과 반드시 붙어 있어야 한다는 것을 안다. 삼중 백틱으로 감싸인 코드 블록은 절대 중간에 잘려서는 안 된다는 것도 안다.
단점은 파서 품질에 크게 의존한다는 점이다. 마크다운용 구조 인식 청커는 HTML이나 PDF용과는 완전히 다르게 작성해야 한다.
HEADING = re.compile(r"^(#{1,6})\s+(.+)$", re.MULTILINE)
_CODE = re.compile(r"```[\s\S]*?```")
_WARNING = re.compile(r"^>\s*\*\*(Warning|Note|Caution)\*\*.*", re.MULTILINE)
from dataclasses import dataclass
@dataclass
class Chunk:
content: str
heading_path: list[str]
doc_id: str
meta: dict
has_code: bool = False
has_table: bool = False
def chunk_structured(text: str, max_tokens: int = 512) -> list[Chunk]:
parts = _HEADING.split(text)
chunks = []
stack = []
if parts[0].strip():
chunks.append(Chunk(
content=parts[0].strip(), heading_path=[], doc_id="",
meta={}, has_code=bool(_CODE.search(parts[0])),
))
for i in range(1, len(parts) - 1, 3):
level = len(parts[i])
title = parts[i + 1].strip()
body = parts[i + 2].strip() if i + 2 < len(parts) else ""
if not body:
continue
while stack and stack[-1][0] >= level:
stack.pop()
stack.append((level, title))
path = [h[1] for h in stack]
sections = _split_preserving_warnings(body, max_tokens)
for sec in sections:
chunks.append(Chunk(
content=sec, heading_path=path, doc_id="", meta={},
has_code=bool(_CODE.search(sec)),
has_table=bool("|" in sec and "---" in sec),
))
return chunks
이 코드는 헤딩 경로를 추적한다. 문서 깊숙이 있는 문단을 추출할 때, 그 문단이 "배포 가이드 → 사전 조건 → 네트워크 설정" 아래에 속한다는 사실을 기억한다. 또한 경고 문구를 찾아서 앞의 텍스트 블록에 붙여준다.
오버랩: 언제 도움이 되고 언제 해가 되는가
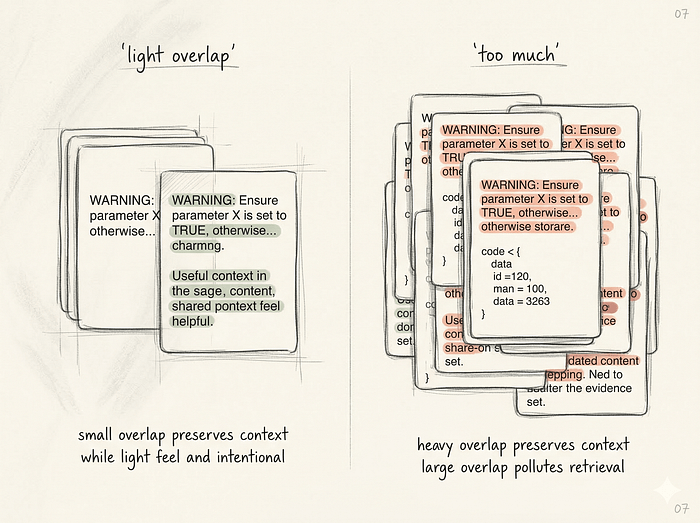
오버랩은 RAG에서 가장 잘못 사용되는 설정값 중 하나다. 대부분의 튜토리얼은 청크 크기 500, 오버랩 50을 권장한다. 사람들은 그 설정을 그대로 복사하고 다시는 생각하지 않는다.
오버랩은 청크 경계 근처의 문맥을 보존하기 위해 존재한다. 문장이 중간에 잘리거나, 다음 청크의 대명사가 이전 청크의 명사를 가리킬 때, 오버랩이 임베딩 모델에게 충분한 문맥을 제공한다.
오버랩이 도움이 되는 경우
- 한 청크에 다 담기지 않는 긴 절차
- 코드와 설명 쌍
- 인접 문맥이 중요한 버전 민감 지침
오버랩이 해가 되는 경우
- 검색 결과 상위 K개가 거의 동일한 청크로 채워진다
- 중복 증거로 컨텍스트 예산을 낭비한다
- 인용이 노이즈가 많고 반복적으로 보인다
오버랩은 공짜 문맥이 아니다. 엄격한 재현율과 정밀도 간의 트레이드오프다. 과도한 오버랩은 대부분 나쁜 청킹의 임시방편이다.
텍스트를 시맨틱 경계에서 잘 분할하면 오버랩이 거의 필요 없다.
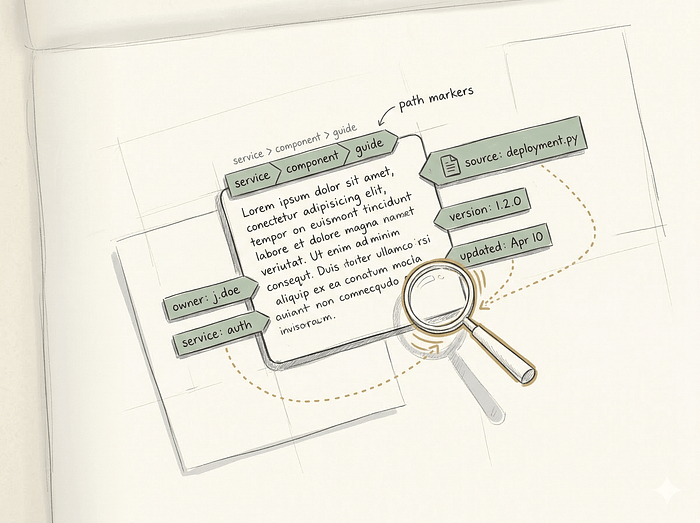
메타데이터와 청킹은 함께 가야 한다
각 청크는 메타데이터를 담아야 한다.
- 소스 문서명, 헤딩/섹션 경로
- 문서 타입, 서비스명, 버전, 업데이트 타임스탬프, 담당 팀
이것이 중요한 이유는 메타데이터 필터링으로 검색 품질이 크게 올라가기 때문이다. 사용자가 "결제 서비스 배포 방법"을 물으면, 벡터 유사도 검색 전에 service_name == "payment" 필터를 먼저 적용할 수 있다. Pinecone, Qdrant 같은 현대적인 벡터 데이터베이스는 쿼리 벡터와 함께 메타데이터 필터를 함께 전달하는 기능을 지원한다.
메타데이터가 없는 청크는 그냥 떠다니는 텍스트다. 현실에 닻을 내리지 못한 텍스트다.
청크를 LLM에게 전달할 때는 이런 식으로 포맷해야 한다.
Source: payment-api-runbook.md
Section: Deploy Guide > Prerequisites
Last Updated: 2026-02-15
Ensure kubectl access and DEPLOY_TOKEN is set.
> **Warning** Without DEPLOY_TOKEN the deploy will silently fail.이 포맷은 LLM이 근거 있는 정확한 답변을 쓰는 데 필요한 문맥을 제공하고, 응답 끝에 정확한 인용을 작성하는 데 필요한 정확한 문자열도 제공한다.
프로덕션에서 청킹 실패가 드러나는 방식
이런 시스템을 만들다 보면, 나쁜 청킹의 증상들을 알아보게 된다. 이것들은 보통 모델 실패처럼 보인다.
"거의 맞는" 답변 검색된 청크가 주제적으로는 관련되어 있지만 실행에는 불충분하다. 사용자가 타임아웃 설정 방법을 묻는다. LLM은 타임아웃이 무엇인지는 설명하지만, 정확한 YAML 문법은 다음 청크에 있어서 놓친다.
마지막 단계 누락 절차의 대부분을 설명하지만, 마지막에 있는 결정적인 명령어나 경고를 빠뜨린다. 사용자는 지침을 따랐다가 환경을 망가뜨린다.
오래된 답변 오래된 문서 버전의 청크가 최신 버전보다 높은 순위를 차지한다. 벡터 유사도는 시간을 이해하지 못한다.
실제로는 쓸모없는 인용 답변이 주장을 부분적으로만 뒷받침하는 청크를 인용한다. 사용자가 링크를 클릭해서 문단을 읽어보면, LLM이 제공한 정확한 명령어가 실제로는 없다는 것을 알게 된다. 청크가 불완전했기 때문에 LLM이 학습 데이터를 기반으로 나머지를 할루시네이션한 것이다.
거대 덩어리 실패 청크 크기를 너무 크게 설정하면, 검색은 기술적으로 작동하지만 프롬프트 조합이 희석된다. LLM이 실제로 중요한 50토큰 주변의 관련 없는 1000토큰 텍스트에 주의가 분산되어 답변 품질이 떨어진다.
작은 단편 실패 정반대 현상이다. 청크가 너무 작아서 모델이 빠진 문맥을 할루시네이션으로 채워야 한다. docker-compose up -d만 있는 청크를 보고 그 주변에 온갖 이야기를 지어낸다.
많은 "모델 실패"는 실제로 청크 설계 실패다. 깨진 증거를 프롬프트로 극복할 수는 없다.
평가 기반 청크 튜닝
안티패턴: 청크 크기를 한 번 정하고, 오버랩을 임의로 추가하고, 검색된 증거를 점검하지 않고, 감으로 튜닝하는 것이다. 설정을 바꾸고, 봇에게 질문하고, 괜찮아 보이면 배포한다.
엔지니어링 접근법: 소규모 평가 셋을 만들고 청킹 전략을 체계적으로 비교한다.
평가해야 하는 것들은 다음과 같다.
- 검색 히트 품질: 상위 3개 청크에 실제 답변이 포함되어 있는가
- 답변 완성도: LLM이 완전한 응답을 작성할 만한 문맥을 가졌는가
- 인용 유용성: 인용이 실제로 주장을 뒷받침하는가
- 청크 일관성: 청크가 그 자체로 의미가 있는가
이를 위해 수천 개의 질문이 필요하지 않다. 실제 사용자 의도를 대표하는 50~100개의 엄선된 질문으로 충분하다.
권장 평가 셋 카테고리는 다음과 같다.
- 정확한 조회 질문: "API 최대 타임아웃은 얼마인가?"
- 절차 따르기 질문: "데이터베이스 마이그레이션을 어떻게 롤백하는가?"
- 트러블슈팅 질문: "auth 서비스에서 502가 나는 이유는 무엇인가?"
- 버전 민감 질문, 설정 질문
from dataclasses import dataclass
@dataclass
class EvalCase:
question: str
expected_chunk_contains: str
category: str
def eval_chunking(
text: str,
cases: list[EvalCase],
strategies: dict[str, callable],
embed_fn: callable,
search_fn: callable,
top_k: int = 3,
) -> dict[str, dict]:
results = {}
for name, chunk_fn in strategies.items():
chunks = chunk_fn(text)
contents = [c.content if hasattr(c, 'content') else c for c in chunks]
chunk_embs = embed_fn(contents)
hits = 0
total = len(cases)
for case in cases:
q_emb = embed_fn([case.question])[0]
idxs = search_fn(q_emb, chunk_embs, top_k)
retrieved = [contents[i] for i in idxs]
if any(case.expected_chunk_contains in r for r in retrieved):
hits += 1
results[name] = {
"hit_rate": hits / total if total else 0,
"num_chunks": len(chunks),
"avg_tokens": sum(len(c.split()) for c in contents) // max(len(contents), 1),
}
return results
이 접근법은 어떤 전략이 실제로 작동하는지 증명할 수 있게 해준다. 구조 인식 청킹이 절차적 질문에서 히트율을 60%에서 85%로 올린다는 것을 확인할 수 있다. 청킹은 경험적으로 튜닝해야 한다. 임의의 블로그 기본값을 그대로 가져와서는 안 된다.

실용적인 기본 전략
오늘 당장 시스템을 만든다면, 기술 문서에 대한 강력한 시작점은 다음과 같다.
구조 인식 재귀 청킹으로 시작한다. 특정 마크다운이나 HTML 형식에 맞는 파서를 작성한다. 헤딩, 코드 블록, 경고, 절차를 원자 단위로 보존한다.
오버랩은 최소한으로 사용한다. 청크가 의미적으로 일관되면 아주 작은 오버랩만으로도 충분하다.
모든 청크에 풍부한 메타데이터를 붙인다. 헤딩 경로를 텍스트 페이로드에 직접 주입해서 임베딩 모델이 볼 수 있게 한다.
임베딩 모델이나 벡터 데이터베이스를 바꾸기 전에 이 기준선을 평가한다. 실제 엔지니어링 문서에 충분히 강력하고, 거대한 리서치 프로젝트를 만들지 않아도 될 만큼 단순하다.
중요한 점은, 문서 타입이 다르면 청킹 규칙도 달라질 수 있다는 것이다. 전체 말뭉치에 하나의 보편적인 청킹 정책을 적용하는 것은 대부분 실수다. Slack 메시지 덤프는 공식 API 명세서와 다른 분할 로직이 필요하다.
배포 전 청킹 튜닝 체크리스트
- [ ] 시맨틱 경계를 보존하고 있는가?
- [ ] 경고 문구가 그것이 수정하는 명령어와 함께 있는가?
- [ ] 코드 블록이 설명과 함께 있는가?
- [ ] 각 청크가 유용한 메타데이터(출처, 헤딩 경로, 버전)를 가지고 있는가?
- [ ] 맹목적이 아닌 의도적으로 오버랩을 사용하고 있는가?
- [ ] 실제 질문으로 청킹 전략을 평가했는가?
- [ ] 디버깅 시 최종 LLM 출력만 보지 않고, 실제 검색된 텍스트를 직접 점검하고 있는가?
결론
청크는 시스템이 다루는 증거의 기본 단위다. 그 단위가 일관되지 않으면, 검색 품질은 조용히 무너진다. 좋은 청킹은 나머지 RAG 파이프라인 전체를 쉽게 만들어준다. 나쁜 청킹은 이후의 모든 컴포넌트가 깨진 증거를 보완하도록 강요한다.
모델을 바꾸기 전에, 벡터 데이터베이스를 업그레이드하기 전에, 그리고 복잡한 멀티 에이전트 루프를 만들기 시작하기 전에 데이터를 먼저 보라. 청크가 실제로 의미 있는지 확인하라.

'최신 AI' 카테고리의 다른 글
| 개발자가 알아야 할 AI 개념들 (1) | 2026.05.15 |
|---|---|
| AI 엔지니어라면 반드시 이해해야 할 9가지 RAG 아키텍처 (0) | 2026.05.14 |
| 개발자의 95%보다 AI를 잘 이해하게 해줄 15가지 개념 (1) | 2026.04.27 |
| AI Agents Explained : 지능형 시스템을 형성하는 6가지 개념 (0) | 2026.04.27 |
| Agentic AI Project: 생성형 AI를 위한 MLflow 관측 - A Deep Dive with Text2SQL + RAG + WebSearch using LangGraph (2) | 2026.04.15 |



